1.- INTRODUCCIÓN
A la hora de recuperarse de un desastre informático, la rapidez constituye el factor primordial. Los costes aumentan rápidamente con cada minuto que transcurre sin que se pueda acceder a sistemas, redes y datos críticos. Ésta es la razón por la cual resulta esencial tener un plan para restaurar los datos, tanto si esto significa replicar la totalidad de nuestro sistema o tan sólo porciones críticas de el, utilizando recursos propios o externos.
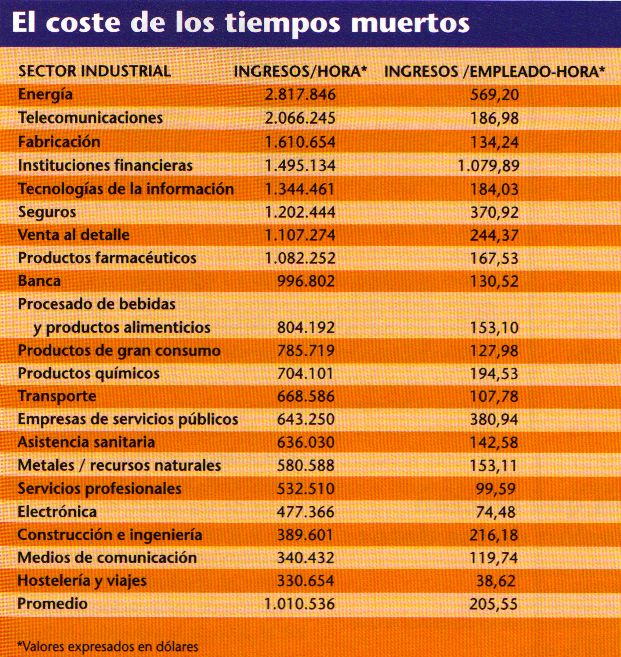
Los costes de los tiempos muertos varían según las industrias, de acuerdo con la dependencia tecnológica y los costes laborales imperantes en cada una de ellas. Según un estudio del Meta Group, aparecido en octubre de 2000, las empresas más dependientes de los sistemas automatizados, tales cama las de suministro de energía y las de telecomunicaciones, acumulan un promedio de cerca de 3 millones de dólares de pérdidas por cada hora de tiempo muerto, que derivan de los ingresos perdidos y de la inactividad de sus empleados. las instituciones financieras y las empresas de fabricación dependientes de las tecnologías informáticas sufren unas pérdidas de 1,5 a 1,6 millones de dólares por hora. Las empresas de asistencia sanitaria, de medios de comunicación y de viajes/hostelería, menos dependientes de las infraestructuras de tecnologías informáticas, pierden ingresos cifrados entre 330.000 y 636.000 dólares por hora
Pero la vulnerabilidad es una cosa relativa. Las pérdidas monetarias quizá no sean su preocupación principal si se halla al frente de, supongamos, una empresa de servicio público, cuyos tiempos muertos de tecnología informática pueden dejar a sus clientes sin calefacción. Las interrupciones de servicio prolongadas también pueden traducirse en una pérdida de confianza por parte de los clientes. Ésta es la vulnerabilidad más importante para incluso el menor negocio electrónico.
Los requisitos modernos, por lo que respecta a recuperación del almacenamiento, presentan un problema de cara a la planificación convencional de la recuperación de un sistema. Con la logística apropiada, pueden efectuarse previsiones para sustituir con rapidez plataformas, redes e, incluso, áreas de trabajo de los usuarios, pero la clave real por lo que atañe a la recuperación es el tiempo necesario para volver a disponer de los datos. La rapidez con que se restauren los datos de forma que puedan ser utilizados de nuevo por las aplicaciones del sistema, por las personas encargadas de la toma de decisiones y por los clientes constituye el determinante último de una recuperación exitosa.
Un plan de recuperación sólido constituye el primer paso de cara a salvar el sistema en caso de que se produzca un desastre en el almacenamiento. La planificación de las copias de seguridad sobre cinta para que sean eficientes y completas resulta indispensable para cualquier plan de este tipo. Cuando las copias de seguridad diarias se convierten en algo imposible de gestionar, significa que ha llegado la hora de tomar en consideración los esquemas de copia incrementales y diferenciales. Reconstruir un servidor a partir de estas copias de seguridad puede ser una operación tediosa, pero es mucho más barata que una colección de copias integrales diarias.
Explosión de datos
Los datos, al igual que el potencial para que se produzca un desastre, crecen en muchas empresas a un ritmo exponencial. Estimaciones conservadoras de International Data Corp. (IDC) sitúan el crecimiento de los datos en, aproximadamente, un 80% anual. Desde unos no tan míseros 184.641 TB de datos almacenados en 1999 en todo el mundo, IDC calcula que el nuevo almacenamiento de datos crecerá hasta casi dos millones TB en 2003.
La mayor parte de este crecimiento puede atribuirse a Internet, el correo electrónico y a las aplicaciones de software «ricas en medios», cada vez más desproporcionadas. Un porcentaje significativo de este crecimiento de los datos puede atribuirse al replicado de datos, un efecto secundario de la carencia de tecnologías de compartición de datos que dispongan de una buena relación coste/eficacia. A todo ello, hay que añadir una abundancia de archivos abandonados, producto de los trabajas de desarrollo de aplicaciones, y de datos obsoletos, que sus creadores utilizaron, olvidaron y no borraron de sus discos duros.
En muchas organizaciones, el crecimiento de los datos reales excluyendo aquellos que son fruto del repicado y los obsoletos- resulta algo menor que la media citada por los analistas, pero no par mucho. Hay pocas empresas que dispongan del tiempo o de la plantilla necesarios para efectuar análisis precisos, y lo cierto es que tampoco hay muchas herramientas automatizadas para gestionar el almacenamiento dentro de los entornos de sistemas distribuidos.
El resultado de todo ello es un diluvio de datos que resulta difícil de segregar en una categoría crítica y otra de no crítica. En ausencia de una clasificación eficaz y de herramientas de gestión para separar los datos que deben
Restaurarse inmediatamente de los que puede tolerar una no disponibilidad más prolongada, en el proceso de copia de seguridad deben incluirse todos los datos.
Situándonos en el escenario posterior a un desastre total, dado el enorme volumen de datos existente en las cintas de seguridad y las comparativamente lentas velocidades de las tecnologías de restauración de datos, resulta fácil comprender que la recuperación de las datos de almacenamiento puede tardar una eternidad horas, e incluso días una vez lograda la restauración de las plataformas servidoras y de las redes.
Para empeorar todavía más las cosas, los fabricantes de utilidades para la restauración de datos afirman que, a pesar de que los datos de los clientes sufren un aumento anual superior al 80%, las solicitudes de compra de capacidad adicional de almacenamiento en disco dentro del entorno de restauración de datos totalizan menos de un 15% de incremento anual. A pesar de las pruebas periódicas que suelen efectuarse, esta disparidad tan aparente en cuanto a requisitos puede que no se descubra hasta que ya sea demasiado tarde.
2.- TOPOLOGÍAS PARA COPIAS DE SEGURIDAD.
Las topologías para almacenamiento dentro de las infraestructuras corporativas de tecnología informáticas han proliferado mucho. El SAS (almacenamiento conectado al servidor) ya no está de moda. Ahora lo que se lleva es el NAS (almacenamiento conectado a la red) y las SAN (redes de área de almacenamiento). Según IDC, desde 1999 hasta 2003, las soluciones de almacenamiento en red van a mostrar una tasa combinada de crecimiento muy alta, cifrada en un 67%, mientras que la tasa de crecimiento para las soluciones de almacenamiento basadas en el modelo de un array de dispositivos conectados a un servidor va a disminuir en el mismo período en un 3%
Evidentemente, las empresas, cuando adquieren componentes de almacenamiento nuevos, no suelen desprenderse de los componentes de almacenamiento antiguos, pero todavía utilizables. Por esta razón, el paso a NAS o a SAN no hace otra cosa que incrementar el número de plataformas sobre las cuales se almacenan los datos, así como el número de objetivos que restaurar tras un desastre.
Las soluciones de almacenamiento en red pueden presentar dificultades especiales que degraden de forma apreciable las velocidades, ya de por sí poco aceptables, de la mayoría de soluciones de restauración de datos basadas en cinta. Por ejemplo, en una SAN, los dispositivos físicos de disco cada vez se hallan más «gestionados» por servidores de dominios de almacenamiento, encaminadores de almacenamiento, productos de virtualización basados en software, o todos ellos, que funcionan proporcionando volúmenes virtuales a servidores conectados a una SAN
Éstos son los que proporcionan el valor real de una SAN, ya que permiten volúmenes escalables de una forma dinámica -incluyendo muchos discos físicos y muchas particiones de arrays de discos distribuidos- capaces de crecer o de encogerse para satisfacer las cambiantes necesidades en cuanto a almacenamiento.
Ante una situación de tener que efectuar la restauración del almacenamiento, estas capas de virtualización SAN también deben actuar como intérpretes, o filtros, que dirijan los flujos de datos de nuevo hacia los discos y particiones destino que conforman el volumen virtual en el que residen normalmente los datos. Éste proceso introduce diversas cuestiones espinosas relacionadas can la forma de mantenimiento de los registros que contienen el diseño de los datos, y la forma que tienen los productos de virtualización de interpretar eficazmente los registros para que los datos se restauren de una forma rápida y conecta.
Varios fabricantes de productos de almacenamiento, entre los que se incluye Ventas Software, han puesto en marcha iniciativas para resolver estos temas, pero todavía no se vislumbran soluciones. Lo que constituye toda una ironía es que los primeros adeptos de la tecnología SAN a menudo citan la realización eficiente de copias de respaldo como una de las razones primarias para haber adoptado la topología. Sin embargo, la restauración constituye una limitación importante para la eficacia de la SAN, especialmente cuando los enfoques de virtualización pasan a ocupar un lugar prominente. Con las nuevas SAN (igual que ocurre hoy día con muchos arrays RAID 5), los datos resultan fáciles de copiar, pero difíciles y lentos de restaurar.
3- EL PROBLEMA DE LA RESTAURACIÓN
Muchos fabricantes de software para efectuar copias de seguridad sobre cinta están de acuerdo en que la industria siempre ha puesto más énfasis en las posibilidades de copia que en las de restauración. Antes del advenimiento de las SAN, que proporcionan un medio para gestionar movimientos de datos a gran escala (copias, replicados de datos, etc.) en una red distinta de la red local de producción, la preocupación principal de los usuarios finales respecto a las copias de seguridad era el tiempo invertido. A medida que las empresas pedían que sus aplicaciones estuvieran operativas 24 horas al día, siete días a la semana, disminuía la posibilidad de desconectar los sistemas para efectuar copias de respaldo. La velocidad con que se efectuaban las copias de seguridad constituía la característica suprema.
Los fabricantes de dispositivos de cinta empezaron a producir formatos de más capacidad, dispositivas más rápidos, bibliotecas robotizadas e, incluso, canales paralelos y RAID de cinta para apoyar los esfuerzos de traspasar los datos de los discos a cintas con mucha más rapidez. La velocidad de restauración a menudo no pasaba de ser una ocurrencia tardía en las decisiones de compra de los clientes; las copias de seguridad eran contempladas cama un engorro necesario, una especie de póliza de seguros a la que uno espera no tener que recurrir nunca jamás.
La velocidad de restauración de los datos (tiempo que se tarda en poder disponer nuevamente de los datos) se ve afectada por diversos factores. Algunas personas serían partidarias de incluir incluso diversos pasos previos -como pueden ser la obtención de las cintas almacenadas fuera del recinto de trabajo, transportarlas hasta la sede donde se efectúa la recuperación, configurarlas dentro de una biblioteca robotizada y verificar la integridad de sus datos- en su calidad de componentes importantes del cálculo del tiempo que se tarda en recuperar los datos. Cuando se utiliza una biblioteca robotizada, se debe añadir el tiempo que tarda el robot en identificar la cinta correcta, «cogerla» y posicionarla en el dispositivo. Dependiendo del fabricante, la selección y carga llevadas a cabo por el robot requiere unos 30 segundos por cinta. Encontrar los datos en la cinta y empezar la transferencia requiere de 30 segundos a 1 minuto, dependiendo del tipo de cinta. Hay que tomar en consideración todos estos factores de tiempo antes de evaluar el proceso real de transferencia de datos.
Una vez la cinta se halla posicionada para efectuar la lectura y restauración de los datos, la velocidad a la erial el dispositivo de cinta es capaz de leer los datos grabados en la cinta constituye un tema importante. En el mundo de los sistemas abiertos, las velocidades medidas al utilizar los formatos de cinta populares oscilan desde los 6 MB por segundo de los dispositivos DLT8000 a los 15 MB por segundo de los dispositivos de cinta LTO Ultrium. El segundo factor lo constituye la velocidad a la cual la interfaz, o la interconexión, del dispositivo (por ejemplo, SCSI o Fibre Channel) pueden transmitir datos al dispositivo destino. Las interconexiones se están aproximando a 1 GB por segundo, pero las posibilidades de los dispositivos de disco de utilizar todo este ancho de banda varían enormemente.
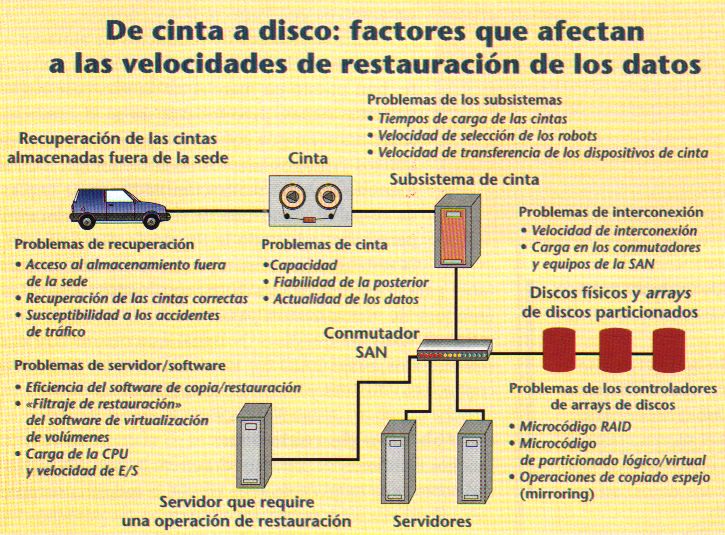
Muchos fabricantes tasan sus posibilidades de restauración de datos tan sólo sobre la base de estos dos factores, creando con ello una impresión bastante engañosa de la velocidad con la que 1 TB de datos puede transferirse de cinta a disco. Según los fabricantes de software, para la realización de copias de seguridad, en el mundo real, la mayoría de usuarios se pueden considerar afortunados en raso de que el rendimiento real de la operación de restauración se aproxime al 30% de la velocidad indicada por el fabricante. Para comprender la razón de ello, tenga en cuenta los siguientes factores atenuantes.
En caso de que los datos de la cinta se envíen directamente a un dispositivo de almacenamiento, la velocidad a la cual el dispositivo puede grabar el flujo de datos procedentes de la cinta constituye un factor importante. El cálculo de la velocidad a la cual los datos pueden grabarse en un solo dispositivo de disco es una tarea sencilla, pero determinar la velocidad de restauración de datos de un array RAID puede constituir todo un reto. Esta se debe a la forma de operar del propio controlador de RAID. Por ejemplo, un controlador de RAID S debe trabajar de forma que asegure que la información de paridad se graba junto con los datos. Realiza dos operaciones de escritura por rada orden de escritura que recibe, lo que da lugar a un retraso apreciable del proceso de grabación de datos. Sin el empleo de soluciones especiales, este retraso puede doblar el tiempo de transferencia de la cinta durante la restauración de los datos (este dilema de la «penalización de la escritura» ha existido durante, por lo menos, dos décadas antes de que aparecieran las SAN, lo que ya anticipaba algunos de los problemas en potencia que iban a presentar los esquemas de virtualización SAN). En un array de discos de gama alta que efectúe tareas RAID a la vez que tareas de virtualización, el controlador podría también ralentizar la restauración de datos debido a que dirige flujos de datos hacia particiones lógicas configuradas dentro del propio array.
La capacidad de los dispositivos de almacenamiento constituye otro factor a tener en cuenta. Hace cosa de 15 años, las capacidades de las cintas excedían las capacidades de los dispositivos de disco habituales en una proporción de 23 a 1. Hacia 1994, el año en que Exabyte presentó su tecnología Mammoth Tape, que proporcionaba una capacidad nativa sin precedentes, de 20 GB, Seagate 'I'echnology empezaba a comercializar su dispositivo de disco para servidores, llamado Barracuda, de 2,1 (GB. Hoy día, la cinta de mayor capacidad dentro del entorno de las sistemas abiertas es la SuperDLT, de 110 GB, de Quantum, mientras que un disco grande de servidor, como el Cheetah, de Seagate, almacena unos 74 GB, lo que equivale a un ratio de 1 a 0,75. Esto prácticamente hace obligatorio el uso de bibliotecas de cinta para restaurar ni que sea una modesta cantidad de datas y constituye una consideración importante a la hora de calcular el tiempo de restauración de los datos para un array de múltiples discos.
A pesar de que las estrategias de copiado y restauración directas de cinta a disco (a veces llamadas «libres de servidor» o «libres de red») cada vez son más populares, existen muchas probabilidades de que en el proceso de restauración se halle implicado un servidor. El servidor será el que albergue una aplicación de software como NetBackup, de Ventas, NetWorker, de Legato, o ARCserve 2000, de Computer Associates, para facilitar la restauración de los datos, y tanto el procesador del servidor como la arquitectura del bus pueden imponer latencias en el proceso de restauración.
Además, los componentes de software, tales como el sistema operativo servidor, el sistema de archivos y la aplicación de restauración, pueden suponer una barrera, al limitar el número de flujos de datos paralelos o concurrentes soportados durante la restauración (Tanto la concurrencia como el paralelismo son dos conceptos que se han introducido para reducir el tiempo invertido en las
de disco). Los sistemas de archivos del servidor también pueden generar sobrecarga durante el proceso de restauración, ya que graban y, a la vez, organizan los datos que se graban en los dispositivos conectados.
Contemplados en conjunto, estos factores distorsionan apreciablemente las estimaciones de los fabricantes referentes a la velocidad de restauración de los datos. Sin tener en cuenta la sobrecarga relacionada con el software, el servidor o la virtualización, los fabricantes estiman que se requieren 24 horas para restaurar, de cinta a disco, 5 TB grabados sobre cintas LTO Ultrium de una biblioteca de cintas. Esta estimación incluye 24 minutos para efectuar el cambio de 13 cintas de 100 GB. Realizar la misma tarea con tecnología DLT8000 requiere 60 horas, de las que 42 minutos se consumen en efectuar el cambio de los cartuchos de cinta de 40 GB. Si a esta ecuación le añadimos esquemas de virtualización, el tiempo requerido para restaurar 5 TB de datos podría ser mucho mayor.
Dadas todas las variables asociadas can una determinada configuración de almacenamiento, resulta fácil comprender por qué los fabricantes no ofrecen garantías de obligado cumplimiento en relación con el rendimiento de las operaciones de restauración de datos. Al igual que ocurre con los automóviles, los kilómetros recorridos pueden variar.
4.-COPIAS ESPEJO
Con todas estas las limitaciones inherentes a las operaciones de restauración de datos de cinta a disco, no resulta sorprendente que muchos proveedores de servicios de restauración de datos ofrezcan como solución la realización de copias espejo de los discos (mirroring). Tanto los fabricantes tradicionales de soluciones para la recuperación de desastres como los recién llegados al mercado de alta disponibilidad, como puedan ser las empresas albergadoras basadas en el Web y los proveedores de servicios de almacenamiento (SSP), lo que buscan es rentabilizar el valor del copiado espejo de los discos para convertirse en los garantes de la supervivencia corporativa.
El copiado espejo abarca un gran número de estrategias, que van desde el replicado simétrico del almacenamiento, casi en tiempo real, hasta el replicado de la sede entera, pasando por las soluciones de replicado asimétricas que se llevan a cabo con un cierto retraso. "Podas estas estrategias tienen dos cosas en común: respecto a las estrategias de recuperación del almacenamiento basadas en cinta, proporcionan ventajas en cuanto al tiempo que se tarda en recuperar los datos, y por otro lado, suelen tener un precio muy elevado.

El copiado espejo, tanto simétrico como asimétrico, no es una tecnología nueva. En una configuración de copiado espejo simétrico, se efectúan operaciones de escritura de datos, casi simultáneas, sobre dos (o más) arrays de discos. Los datos se escriben sobre el Array 1, y luego las actualizaciones de este conjunta se mantienen en una cola hasta que la misma operación de escritura pueda efectuarse en el Array 2. En el pasado, el copiado espejo simétrico tan sólo resultaba práctico dentro de los confines de un centro de datos, con los arrays espejos situados uno al lado del otro. El hecho de colocar el array secundario a una distancia apreciable del primario daba lugar a un retraso ocasionado por la latencia y a un rendimiento deficiente del sistema global. A medida que en las grandes ciudades se van desplegando redes metropolitanas (MAN) de alta velocidad, el hecho de disponer de mayor ancho de banda convierte en práctico al copiado espejo simétrico.
Tanto los SSP como los proveedores tradicionales de soluciones para la recuperación de desastres hablan de un incremento de las suscripciones a sus servicios de copiado espejo simétrico, si bien los clientes tienden a ser empresas tipo Fortune 1000 u otras empresas condenadas a sufrir grandes pérdidas aún en caso de un parón, ni que sea mínimo.
En caso de que una empresa no tenga acceso a una red metropolitana de fibra óptica que funcione a velocidades de operadora ni se pueda permitir tender fibra ella misma, el copiado espejo asimétrico constituye una alternativa. Éste, generalmente, implica el uso de tres arrays de discos: los arrays 1 y 2 se hallan uno al lado del otro y constituyen la copia espejo del otro. Los arrays 2 y 3, que son geográficamente rematas entre sí, se comunican datos espejo a través de una red más lenta. Dada su calidad de operación, aparte de copiado espejo, los intercambios entre los arrays 2 y 3 no imponen ninguna penalización por latencia sobre los sistemas de producción ni sobre los de copiado espejo.
Evidentemente, en un copiado espejo asimétrico, los datos almacenados en el array 3 jamás se hallan sincronizados con los del array 2. La amplitud del «desfase de copia espejo» -la diferencia entre los datos de ambos conjuntos- viene determinada por la distancia entre los arrays y por el ancho de banda de la red de interconexión. Cualquier empresa que considere la posibilidad de utilizar esta opción debe sopesar los costes que supone la pérdida de algunas transacciones frente a las ventajas de tener la mayor parte de los datos listos para ser usados en caso de que se produzca una interrupción no planificada. Además, en el análisis coste/beneficio también se debe tener en cuenta el coste no de dos arrays de discos, sino de tres, y el coste de la red entre sedes.
Lo anterior también es aplicable a los preparativos de copiado espejo que impliquen el uso de una SAN. Con una SAN, los datos pueden encaminarse hacia destinos múltiples con la ayuda de un conmutador. En este caso, las inversiones más costosas e indispensables incluyen el coste de una infraestructura de almacenamiento idéntica (o compatible) situada en una localización remota, y el ancho de banda empleado por la solución. Un número cada vez mayor de proveedores de recuperación y de SSP han puesto en práctica un menú de ofertas de servicio que proporcionan la recuperación de los datos al cabo de una cierta cantidad de tiempo, que depende del precio pactado. Tampoco hay que ignorar los servicios de hospedaje basados en el Web, los llamados centros de datos de la nueva era. Cada vez más, estas organizaciones están rentabilizando sus infraestructuras dotadas con ubicaciones múltiples, interconectadas mediante redes operadoras, como panacea para aquellas empresas que necesitan disponer de estrategias de recuperación de instalaciones y de almacenamiento de alta disponibilidad. Si la infraestructura de tecnología informática utiliza un modelo de centro de datos montado sobre un bastidor, cualquier empresa de hospedaje Web puede ser capaz de satisfacer todas, o parte, de sus estrategias de recuperación gracias a sus servicios de recuperación mediante copias espejo de los discos.
A1 revés de la posición adoptada por algunas fabricantes de arrays de discos, hay que puntualizar que el copiado espejo no constituye en absoluto una sustitución de la cinta. El copiado espejo resulta bastante proclive a provocar paradas atribuibles a los datos, debidas a corrupciones ocasionadas por aplicaciones deficientes y maliciosas. Cuando en uno de los conjuntos de discos integrantes de una copia espejo se graban datos erróneos, éstos se replican en el otro. Sin algún medio para restaurar datos hasta alcanzar un estado precorrupto, tal como una copia de datos sobre cinta, una estrategia de copiado espejo no podría constituir el mecanismo de recuperación de almacenamiento a prueba de bombas que los planificadores de la continuidad de los negocios esperan que sea.
5.- ARREGLO REDUNDANTE DE DISCOS INDEPENDIENTES (ARRAY)
No es un nuevo insecticida. El concepto de RAID fue desarrollado por un grupo de científicos en la Universidad de California en Berkley en 1987. Los científicos investigaban usando pequeños HD unidos en un arreglo (definido como dos o más HD agrupados para aparecer como un dispositivo único para el servidor) y compararon el desempeño y los costos de este tipo de configuración de almacenamiento con el uso de un SLED (Single Large Expensive Disk), común en aplicaciones de MainFrames.
Su conclusión fue que los arreglos de HD pequeños y poco costosos ofrecían el mismo o un mejor desempeño que los SLED. Sin embargo, dado que había mas discos usados en un arreglo el MTBDL (Mean Time Be fore Data Loss) -calculado dividiendo el MTBF (Mean Time Between Failures) por el número de discos en el arreglo- sería inaceptablemente bajo.
Los problemas entonces fueron como manejar el MTBF y prevenir que la falla de un solo HD causara pérdida de datos en el arreglo. Para mejorar esto, propusieron 5 tipos de arreglos redundantes, Definiéndolas como RAID Nivel 1 hasta 5. El nivel del RAID es Simplemente la arquitectura que determina como se logra la redundancia y como los datos están distribuidos a través de los HD del arreglo.
Adicional al RAID 1 hasta 5, una configuración de arreglo no redundante que emplea partición de datos (esto es partir los archivos en bloques pequeños y distribuir estos bloques a través de los HD del arreglo), esto es conocido como RAID 0.
DEFINICIONES:
RAID 0
También llamado partición de los discos, los datos son distribuidos a través de discos paralelos. RAID 0 distribuye los datos rápidamente a los usuarios, pero no ofrece mas protección a fallas de hardware que un simple disco.
RAID 1
También llamado Disk mirroring provee la más alta medida de protección de datos a través de una completa redundancia. Los datos son copiados a dos discos simultáneamente. La disponibilidad es alta pero el costo también dado que los usuarios deben comprar dos veces la capacidad de almacenamiento que requieren.
RAID 0/1
Combina Disk mirroring y partición de datos. El resultado es gran disponibilidad al más alto desempeño de entrada y de salida para las aplicaciones de negocios mas criticas. A este nivel como en el RAID 1 los discos so n duplicados. Dado que son relativamente no costosos, RAID 0/1 es una alternativa para los negocios que necesitan solamente uno o dos discos para sus datos, sin embargo, el costo puede convertirse en un problema cuando se requieren mas de dos discos.
RAID 3
Logra redundancia sin mirroring completo. El flujo de los datos es particionado a través de todos los HD de datos en el arreglo. La información extra que provee la redundancia esta escrito en un HD dedicado a la parida d. Si cualquier HD del arreglo falla, los datos perdidos pueden ser reconstruidos matemáticamente desde los miembros restantes del arreglo. RAID 3 es especialmente apropiado para procesamiento de imagen, colección de datos científicos, y otras aplicaciones en las cuales grandes bloques de datos guardados secuencialmente deben ser transferidos rápidamente
RAID 5
Todos los HD en el arreglo operan independientemente. Un registro entero de datos es almacenado en un solo disco, permitiendo al arreglo satisfacer múltiples requerimientos de entrada y salida al mismo tiempo. La información de paridad esta distribuida en todos los discos, aliviando el cuello de botella de acceder un solo disco de paridad durante operaciones de entrada y salida concurrentes. RAID 5 está bien recomendado para procesos de transacciones on-line, automatización de oficinas, y otras aplicaciones caracterizadas por gran numero de requerimientos concurrentes de lectura. RAID 5 provee accesos rápidos a los datos y una gran medida de protección por un costo mas bajo que el Disk Mirroring
RAID 10
La información se distribuye en bloques como en RAID-0 y adicionalmente, cada disco se duplica como RAID-1, creando un segundo nivel de arreglo. Se conoce como "striping de arreglos duplicados". Se requieren, dos canales, dos discos para cada canal y se utiliza el 50% de la capacidad para información de control. Este nivel ofrece un 100% de redundancia de la información y un soporte para grandes volúmenes de datos, donde el precio no es un factor importan te. Ideal para sistemas de misión crítica donde se requiera mayor confiabilidad de la información, ya que pueden fallar dos discos inclusive (uno por cada canal) y los datos todavía se mantienen en línea. Es apropiado también en escrituras aleatorias pequeñas.
RAID 30
Se conoce también como "striping de arreglos de paridad dedicada". La información es distribuida a través de los discos, como en RAID-0, y utiliza paridad dedicada, como RAID-3 en un segundo canal. Proporciona una alta confiabilidad, igual que el RAID-10, ya que también es capaz de tolerar dos fallas físicas de discos en canales diferentes, manteniendo la información disponible. RAID-30 es el mejor para aplicaciones no interactivas, tales como señales de video, gráficos e imágenes que procesan secuencialmente grandes archivos y requieren alta velocidad y disponibilidad.
RAID 50
Con un nivel de RAID-50, la información se reparte en los discos y se usa paridad distribuida, por eso se conoce como "striping de arreglos de paridad distribuida". Se logra confiabilidad de la información, un buen rendimiento en general y además soporta grandes volúmenes de datos. Igualmente, si dos discos sufren fallas físicas en diferentes canales, la información no se pierde. RAID-50 es ideal para aplicaciones que requieran un almacenamiento altamente confiable, una elevada tasa de lectura y un buen rendimiento en la transferencia de datos. A este nivel se encuentran aplicaciones de oficina con muchos usuarios accediendo pequeños archivos, al igual que procesamiento de transacciones.
6.- DISPOSITIVOS DE COPIAS DE SEGURIDAD
En la actualidad se pueden hacer las copias de seguridad en multitud de de medios físicos, y las capacidades que se alcanzan son cada vez mayores. Las tecnologías ópticas (CD-ROM) dan posibilidades de hacer copias baratas y rápidas desde la proliferación de grabadoras y regrabadoras de CD-ROM. Además, el formato en CD-ROM es poco más o menos que universal, y no sería difícil de encontrar un equipo con su dispositivo lector de CD-ROM. El único problema que presentan estos tipos de dispositivos es la baja capacidad (entre 650 y 700 MB), pero pueden ser perfectamente válidos para copias caseras y sistemas de poco volumen.
Por otra parte están los arrays de discos de cambio en caliente (hot swap); estos dispositivos están compuestos de multitud de discos duros, los cuales pueden sacarse y meterse en el array sin necesidad de apagarlo, y sin que el sistema pierda ni un ápice de rendimiento. La disminución de precios que están sufriendo los discos duros, tanto SCSI como IDE, y la mayor rapidez que cada vez más van adquiriendo (SCSI 160 MB/S o SCSI III y ULTRA ATA 100) los hacen ser buenas opciones para empresas medianas/grandes.
Por último, las copias en soporte magnético siguen siendo los soportes más populares a la hora de realizar las copias de seguridad. Estos dispositivos se componen de una cinta de sustrato de polímero de anchura variable, recubierto con varias capas de material magnético con una densidad determinada. Esta cinta puede ser también un disco de material magnético, aunque esto se utiliza menos, debido a su poca capacidad y lentitud. Las cintas fueron los primeros dispositivos sobre los que se hicieron copias de seguridad y en la actualidad siguen siendo el método más utilizado en grandes servidores corporativos. Además, las cintas se pueden agrupar en las denominadas bibliotecas de cintas, que no es nada más que un robot con conexión a red, y el mismo es capaz de posicionar las cintas al lector.
A continuación vemos una tabla comparativa entre diversos soportes.
|
Comparación de diferentes medios de almacenamiento secundario |
|||
|
Dispositivo |
Fiabilidad |
Capacidad |
Coste/MB |
|
Disquete |
Baja |
Baja |
Alto |
|
CD-ROM |
Media |
Media |
Bajo |
|
Disco duro |
Alta |
Media/Alta |
Medio. |
|
Cinta 8mm. |
Media |
Alta |
Medio. |
|
Cinta DAT |
Alta |
Alta |
Medio |
7.- Políticas de copias de seguridad
La forma más elemental de realizar una copia de seguridad consiste simplemente en volcar los archivos a salvaguardar a un dispositivo de backup, con el procedimiento que sea; por ejemplo, si deseamos guardar todo el contenido del directorio /export/home/, podemos empaquetarlo en un archivo, comprimirlo y a continuación almacenarlo en una cinta:
miservidor:~# tar cf backup.tar /export/home/
miservidor:~# compress backup.tar
miservidor:~# dd if=backup.tar.Z of=/dev/rmt/0
Si en lugar de una cinta quisiéramos utilizar otro disco duro, por ejemplo montado en /mnt/, podemos simplemente copiar los ficheros deseados:
miservidor:~# cp -rp /export/home/ /mnt/
Esta forma de realizar backups volcando en el dispositivo de copia los archivos o directorios deseados se denomina copia de seguridad completa o de nivel 0. Unix utiliza el concepto de nivel de copia de seguridad para distinguir diferentes tipos de backups: una copia de cierto nivel almacena los archivos modificados desde el último backup de nivel inferior. Así, las copias completas son, por definición, las de nivel 0; las copias de nivel 1 guardan los archivos modificados desde la última copia de nivel 0 (es decir, desde el último backup completo), mientras que las de nivel 2 guardan los archivos modificados desde la última copia de nivel 1, y así sucesivamente (en realidad, el nivel máximo utilizado en la práctica es el 2).
Como hemos dicho, las copias completas constituyen la política más básica para realizar backups, y como todas las políticas tiene ventajas e inconvenientes; la principal ventaja de las copias completas es su facilidad de realización y, dependiendo del mecanismo utilizado, la facilidad que ofrecen para restaurar ficheros en algunas situaciones: si nos hemos limitado a copiar una serie de directorios a otro disco y necesitamos restaurar cierto archivo, no tenemos más que montar el disco de backup y copiar el fichero solicitado a su ubicación original.
Sin embargo, las copias completas presentan graves inconvenientes; uno de ellos es la dificultad para restaurar ficheros si utilizamos múltiples dispositivos de copia de seguridad (por ejemplo, varias cintas). Otro inconveniente, más importante, de las copias de nivel 0 es la cantidad de recursos que consumen, tanto en tiempo como en hardware; para solucionar el problema de la cantidad de recursos utilizados aparece el concepto de copia de seguridad incremental. Un backup incremental o progresivo consiste en copiar solamente los archivos que han cambiado desde la realización de otra copia (incremental o total). Por ejemplo, si hace una semana realizamos un backup de nivel 0 en nuestro sistema y deseamos una copia incremental con respecto a él, hemos de guardar los ficheros modificados en los últimos siete días (copia de nivel 1); podemos localizar estos ficheros con la orden find:
miservidor:~# find /export/home/ -mtime 7 -print
Si hace un día ya realizamos una copia incremental y ahora queremos hacer otra copia progresiva con respecto a ella, hemos de almacenar únicamente los archivos modificados en las últimas 24 horas (copia de nivel 2); como antes, podemos utilizar find para localizar los archivos modificados en este intervalo de tiempo:
miservidor:~# find /export/home/ -mtime 1 -print
Esta política de realizar copias de seguridad sobre la última progresiva se denomina de copia de seguridad diferencial.
La principal ventaja de las copias progresivas es que requieren menos tiempo para ser realizadas y menos capacidad de almacenamiento que las completas; sin embargo, como desventajas tenemos que la restauración de ficheros puede ser más compleja que con las copias de nivel 0, y también que un solo fallo en uno de los dispositivos de almacenamiento puede provocar la pérdida de gran cantidad de archivos; para restaurar completamente un sistema, debemos restaurar la copia más reciente de cada nivel, en orden, comenzando por la de nivel 0. De esta forma, parece lógico que la estrategia seguida sea un término medio entre las vistas aquí, una política de copias de seguridad que mezcle el enfoque completo y el progresivo: una estrategia muy habitual, tanto por su simpleza como porque no requiere mucho hardware consiste en realizar periódicamente copias de seguridad de nivel 0, y entre ellas realizar ciertas copias progresivas de nivel 1. Por ejemplo, imaginemos un departamento que decide realizar cada domingo una copia de seguridad completa de sus directorios de usuario y de /etc/, y una progresiva sobre ella, pero sólo de los directorios de usuario, cada día lectivo de la semana. Un shellscript que realize esta tarea puede ser el siguiente:
#!/bin/sh
DIA=`date +%a` # Dia de la semana
DIREC="/tmp/backup/" # Un directorio para hacer el backup
hazback () {
cd $DIREC
tar cf backup.tar $FILES
compress backup.tar
dd if=backup.tar.Z of=/dev/rmt/0
rm -f backup.tar.Z
}
if [ ! -d $DIREC ];
then
# No existe $DIREC
mkdir -p $DIREC
chmod 700 $DIREC # Por seguridad
else
rm -rf $DIREC
mkdir -p $DIREC
chmod 700 $DIREC
fi;
case $DIA in
"Mon")
# Lunes, progresiva
FILES=`find /export/home/ -mtime 1 -print`
hazback
;;
"Tue")
# Martes, progresiva
FILES=`find /export/home/ -mtime 2 -print`
hazback
;;
"Wed")
# Miercoles, progresiva
FILES=`find /export/home/ -mtime 3 -print`
hazback
;;
"Thu")
# Jueves, progresiva
FILES=`find /export/home/ -mtime 4 -print`
hazback
;;
"Fri")
# Viernes, progresiva
FILES=`find /export/home/ -mtime 5 -print`
hazback
;;
"Sat")
# Sabado, descansamos...
;;
"Sun")
# Domingo, copia completa de /export/home y /etc
FILES="/export/home/ /etc/"
hazback
;;
esac
Este programa determina el día de la semana y en función de él realiza - o no, si es sábado - una copia de los ficheros correspondientes (nótese el uso de las comillas inversas en la orden find). Podríamos automatizarlo mediante la facilidad cron de nuestro sistema para que se ejecute, por ejemplo, cada día a las tres del mediodía (una hora en la que la actividad del sistema no será muy alta); de esta forma, como administradores, sólo deberíamos preocuparnos por cambiar las cintas cada día, y dejar una preparada para el fin de semana. Si decidimos planificarlo para que se ejecute de madrugada, hemos de tener en cuenta que el backup de un lunes de madrugada, antes de llegar al trabajo, puede sobreescribir el completo, realizado el domingo de madrugada, por lo que habría que modificar el shellscript; también hemos de estar atentos a situaciones inesperadas, como que no existan archivos a copiar o que nuestro sistema no disponga del suficiente disco duro para almacenar temporalmente la copia.
El medio de almacenamiento también es importante a la hora de diseñar una política de copias de seguridad correcta. Si se trata de dispositivos baratos, como los CD-ROMs, no suele haber muchos problemas: para cada volcado (sea del tipo que sea) se utiliza una unidad diferente, unidad que además no se suele volver a utilizar a no ser que se necesite recuperar los datos; el uso de unidades regrabables en este caso es minoritario y poco recomendable, por lo que no vamos a entrar en él. No obstante, algo muy diferente son los medios de almacenamiento más caros, generalmente las cintas magnéticas; al ser ahora el precio algo a tener más en cuenta, lo habitual es reutilizar unidades, sobreescribir las copias de seguridad más antiguas con otras más actualizadas. Esto puede llegar a convertirse en un grave problema si por cualquier motivo reutilizamos cintas de las que necesitamos recuperar información; aparte del desgaste físico del medio, podemos llegar a extremos en los que se pierda toda la información guardada: imaginemos, por ejemplo, que sólo utilizamos una cinta de 8mm. para crear backups del sistema: aunque habitualmente todo funcione correctamente (se cumple de forma estricta la política de copias, se verifican, se almacenan en un lugar seguro...), puede darse el caso de que durante el proceso de copia se produzca un incendio en la sala de operaciones, incendio que destruirá tanto nuestro sistema como la cinta donde guardamos su backup, con lo que habremos perdido toda nuestra información. Aunque este es un ejemplo quizás algo extremo, podemos pensar en lugares donde se utilicen de forma incorrecta varios juegos de copias o en situaciones en las que el sistema se corrompe (no ha de tratarse necesariamente de algo tan poco frecuente como un incendio, sino que se puede tratar de un simple corte de fluido eléctrico que dañe los discos); debemos asegurarnos siempre de que podremos recuperar con una probabilidad alta la última copia de seguridad realizada sobre cada archivo importante de nuestro sistema, especialmente sobre las bases de datos.
APÉNDICE A – Tres scripts para hacer copias de seguridad y restaurar en Linux/UNIX con cpio.
Backup integral de un sistema Linux/UNIX
##########################################################################
#
# BACKUP INTEGRAL DEL SISTEMA AMB CPIO
#
# La llista de fitxers es guardarà en /admin/backup/files/cpio.f.mmdd
# on mm = mes i dd = dia.
#
##########################################################################
DEVICE=/dev/tape
US="Uso: $0 [directori]"
LLISTA=/admin/backup/files/cpio.i.`date +%m%d`
LOGFILE=/admin/backup/files/log
case $# in
0)
DIR=/
echo "Backup de tot el directori '/'"
;;
1)
if [! -d "$1"]
then
echo "ERROR: '$1' NO ES UN DIRECTORI"
echo $US
exit 1
fi
DIR="$1"
echo "Backup del directori $1"
;;
*)
echo $US
exit 2
;;
esac
cd $DIR
find . -newer $LOGFILE -print | tee $LLISTA | cpio -ocavB > $DEVICE
echo "$0: `date`" >> $LOGFILE
echo "Backup de $* en curs" >> $LOGFILE
Backup incremental de un sistema Linux/UNIX
##########################################################
#
# BACKUP INCREMENTAL DEL SISTEMA
# O D’UN DIRECTORI I ELS SEUS SUBDIRECTORIS
#
# C P I O
#
# La llista de fitxers es guardarà en /admin/backup/files/cpio.f.mmdd
# on mm = mes i dd = dia.
#
#############################################################
DEVICE=/dev/tape
US="Us: $0 [directori]"
LLISTA=/admin/backup/files/cpio.i.`date +%m%d`
LOGFILE=/admin/backup/files/log
case $# in
0)
DIR=/
echo "Backup de tot el directori '/'"
;;
1)
if [! -d "$1"]
then
echo "ERROR: '$1' NO ES UN DIRECTORI"
echo $US
exit 1
fi
DIR="$1"
echo "Backup del directori $1"
;;
*)
echo $US
exit 2
;;
esac
cd $DIR
find . -newer $LOGFILE -print | tee $LLISTA | cpio -ocavB > $DEVICE
echo "$0: `date`" >> $LOGFILE
echo "Backup de $* en curs" >> $LOGFILE
Restore interactivo de un sistema Linux/UNIX
##########################################################################
#
# RESTORE DE UN SISTEMA DE FITXERS
# A PARTIR DE LA CINTA
#
# C P I O
#
# La llista de fitxers es guardarà en /admin/backup/files/cpio.f.mmdd
# on mm = mes i dd = dia.
#
###########################################################################
DEVICE=/dev/tape
US="Uso: $0 [arxius]"
LLISTA=/admin/backup/files/cpio.i.`date +%m%d`
LOGFILE=/admin/backup/files/log
case $# in
0)
echo $US
exit 1
;;
1)
if [! -d "$1"]
then
echo "ERROR: '$1' NO ES UN DIRECTORI"
exit 2
fi
echo "$0: `date`" >> $LOGFILE
echo "Restauració del directori $1"
echo "Restauració en curs del directori $1" >> $LOGFILE
cpio -icvdmB < $DEVICE
;;
*)
cd "$1"
echo "$0: `date`" >> $LOGFILE
shift
echo "Restauració de directoris/fitxers $*"
echo "Restauració de $* en curs" >> $LOGFILE
cpio -icvdmB $* < $DEVICE
;;
esac
echo Restauració acabada