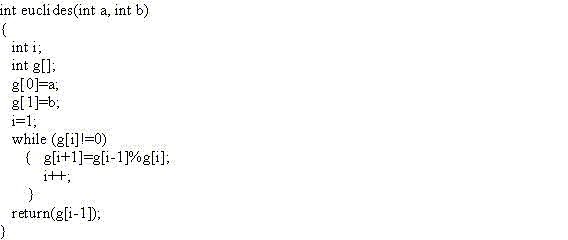
tema 1: La problemática de la seguridad
tema 2: Fundamentos de la criptografía
tema 5: Seguridad en sistemas operativos
1. Conceptos básicos
Información:
Entendemos por información el conjunto de datos que sirven para tomar una decisión.
En cuanto a su implementación se puede hablar de:
Es un subconjunto del subsistema formalizado, con distinto grado de cobertura. Por otra parte, se puede ver el sistema informático como el conjunto de los recursos técnicos, financieros y humanos cuyo objetivo consiste en el almacenamiento, procesamiento y transmisión de la información de la empresa.
Seguridad informática:
Definimos seguridad informática como todo aquel conjunto de medidas de cualquier tipo que intente preservar la siguiente serie de propiedades:
Algunas reglas básicas a la hora de establecer una política de seguridad son:
1. Determinar los recursos a proteger y su valor.
2. Analizar las vulnerabilidades y amenazas de nuestro sistema, su
probabilidad y su coste.
3. Definir las medidas a establecer para proteger el sistema.
4. Monitorizar el cumplimiento de la política y revisarla
y mejorarla cada vez que se detecte un problema.
3. Análisis y gestión de riesgos
Cr: Valor de nuestro sistema informático, esto es, de los recursos y la información a proteger.
Ca: Coste de los medios necesarios para romper las medidas de seguridad establecidas en nuestro sistema.
Cs: Coste de las medidas de seguridad.
Para que la política de seguridad de nuestro sistema sea lógica debe cumplirse la siguiente relación:
Ca>Cr>Cs
El que Ca sea mayor que Cr significa que el ataque para romper nuestro sistema debe ser más costoso que su valor.
El que Cr sea mayor que Cs significa que no debe costar más proteger la información que la información protegida, ya que en este caso no es conveniente no protegerla.
4. Vulnerabilidad, amenazas y contramedidas
Ciertos fallos o debilidades del software del sistema hacen más fácil acceder al mismo y lo hacen menos fiable.
Los usuarios del sistema también suponen un gran riesgo al mismo. Ellos son los que pueden acceder al mismo, tanto físicamente como mediante conexión.
Según el efecto causado en el sistema:
Son los más difíciles de detectar pues en la mayoría de los casos no alteran la información o el sistema.
Existen 3 factores fundamentales a considerar:
Podemos destacar los siguientes controles lógicos:
La recuperación de la información se basa en una política de copias de seguridad adecuada, mientras la recuperación del funcionamiento del sistema se basa en la preparación de unos recursos alternativos.
Una buena política de copias de seguridad debe contemplar los siguientes aspectos:
Es un conjunto de técnicas que ocultan la información frente a observadores no autorizados. Mediante formulas matemáticas se transforman los datos en una información inteligible, que será el texto cifrado.
Para descifrar la información necesitaremos una clave, a partir de la cual se recuperarán los datos iniciales.
Criptosistema
Definiremos un criptosistema como una quíntupla (M, C, K, E, D), donde:
Ck ( Ek(m))=m
En este caso hay dos posibles métodos de cifrado:
M = Dp(Ek(m)) y
M = Dk(Ep(m))
El RSA es uno de los algoritmos asimétricos más seguros. Se basa en la dificultad para factorizar grandes números. Las claves pública y privada se calculan a partir de un número que se obtiene como producto de os primos grandes.
En la practica se emplea una combinación de ambas, se codifican los mensajes mediante algoritmos simétricos y se usa la criptografía asimétrica para codificar las claves asimétricas.
Consiste en comprometer la seguridad de un criptosistema. Esto se puede hacer descifrando un mensaje sin conocer la llave, o bien obteniendo a partir de uno o más criptogramas la clave que ha sido empleada en sui codificación.
Cantidad de información
El concepto de cantidad de información es cuantificable y se puede definir mediante la siguiente expresión:
Ii =-log2(P(xi))
Donde,
xi representa el suceso i-ésimo y P(xi) representa la probabilidad asociada a dicho suceso.
Entropía
Efectuando una suma ponderada de las cantidades de información de todos los posibles estados de una variable aleatoria V, obtenemos:
H(V)=-å (i=1,n)P(xi)log2[P(xi)]
Siendo H(V) la entropía de la variable aleatoria V. Sus propiedades son las siguientes:
1. 0 £ H(V) £
log2N
2. H(V) = 0 Û $
i tal que P(xi) = 1 y P(xj) = 0 "
i ¹ j
3. H(x1,x2
xn) = H(x1,x2
xn, xn+1) si P(xn+1) = 0
Entropía condicionada de un suceso sobre otro
H(x/y) = -å (i=1,n)å (j=1,m)P(xi,yj)log2 P(xi / yj)
Ley de las entropías totales:
H(x, y) = H(x) + H(y / x)
Cumpliéndose además si x e y son independientes:
H(x, y) = H(x) + H(y)
Teorema:
H(x /y) £ H(x)
El conocimiento de una variable nos puede dar información sobre la otra.
Cantidad de información entre dos variables
Se define la cantidad de información de Shannon que la variable x contiene sobre y como:
I(x, y) = H(y) H(y / x)
Sus propiedades son las siguientes:
Diremos que un criptosistema es seguro si la cantidad d e información que nos aporta el hecho de conocer el mensaje cifrado (c) sobre la entropía del texto claro(m) vale cero, es decir:
I(C, M) = 0
Esto significaría que el conocimiento del conjunto C no nos aporta ninguna información del conjunto M.
Los criptosistemas que cumplen la condición de Shannon de denominan criptosistemas ideales, ya que no podríamos romperlo aunque utilizáramos una máquina con capacidad e proceso infinito, por el contrario si no la cumple podríamos romperlo.
Índice del lenguaje:
Mide el número de bits de información que nos aporta cada carácter en mensajes de una longitud determinada.
rk = Hk(M) / K
Índice absoluto de un lenguaje:
Es el máximo número de bits de información que pueden ser codificados en cada carácter, asumiendo que todas las combinaciones de caracteres son igualmente probables.
R = log2(n)
Siendo n el número de símbolos diferentes en nuestro lenguaje.
Redundancia:
Mide el exceso de información de un lenguaje. Se define como la diferencia entre índice absoluto de un lenguaje y índice del lenguaje:
D = R - rk
Índice de redundancia:
I = D / R
Desinformación de un criptosistema:
H(M, C) = -å (mÎ M)å (cÎ C)P(c)P(m/c)log2(P(m/c))
Esta expresión nos permite saber la incertidumbre que nos queda sobre cuál ha sido el mensaje enviado, m, si conocemos su criptograma asociado c.
Si H(M) = H(M / C) C y M son variables estadísticamente independientes (criptosistema seguro de Shannon).
Si H(M / C) < H(M) hay alguna relación entre C y M (lo habitual).
Si H(M / C) = 0 conociendo c podemos obtener m (el peor caso)
Distancia de unicidad:
Longitud mínima e mensaje cifrado que aproxima el valor H(K / C) a cero. Es decir, es la cantidad de texto cifrado que necesitamos para descubrir la clave.
Técnicas fundamentales
Confusión: Trata de ocultar la relación entre el texto claro y el texto cifrado. El mecanismo más simple de confusión es la sustitución, que consiste en cambiar cada ocurrencia de un símbolo en el texto claro por otro.
Difusión: Diluye la redundancia del texto claro repartiéndola a lo largo de todo el texto cifrado. El mecanismo más elemental es la transposición, que consiste en cambiar de sitio elementos individuales del texto claro.
Aritmética modular
Congruencia modulo n
Decimos que a es congruente con b módulo n, y se escribe:
a º b (mod n)
si se cumple:
a = b + kn, para algún k Î Z.
Por ejemplo 37º 5 ( mod 8) , ya que 37 = 5 + 4*8.
Algoritmo de Euclides
Permite obtener de forma eficiente el máximo común divisor de dos números. Sean a y b dos números enteros de los que queremos calcular su máximo común divisor m. El algoritmo de Euclides cumple la siguiente propiedad:
m|a L m|b Þ m|(a-kb) con k Î Z Þ m|(a mod b)
a|b quiere decir que a divide a b y (a mod b) es el resto de dividir a entre b.
M tiene que dividir a todos los restos que vayamos obteniendo. El
penúltimo valor obtenido es el máximo común divisor
de ambos, ya que será el mayor número que divide tanto a
a como a b. El algoritmo será:
Números primos entre sí
Dos números enteros a y b se denominan primos entre sí, si mcd(a, b)=1.
TEOREMA: Existencia de la inversa
Si m.c.d(a, n) = 1 , entonces $ a-1 modulo n
FUNCIÓN DE EULER
CRRmod n: conjunto reducido de residuos modulo n
Llamaremos conjunto reducido de residuos modulo n al conjunto de números primos relativos con n, es decir, el conjunto de todos los números que tienen inversa módulo n.
Existe una expresión que nos permite calcular el número de elementos del conjunto reducido de residuos módulo n, que es la función de Euler y es la siguiente:
f(n) = Õi=1piei-1(pi-1)
siendo
pi los factores primos de n y ei su multiplicidad
Por ejemplo si n fuera el producto de dos números primos p y q, entonces:
f (n) = (p-1)(q-1)
Teorema:
Si m.c.d(a, n) = 1 Þ af(n) º 1 (mod n)
Teorema de Fermat:
Si p es primo , entonces ap-1 º 1 (mod p)
La función de Euler es uno de los posibles métodos para calcular inversas módulo n, ya que:
af(n) = aaf(n)-1 º 1 (mod n) Þ a-1 º af(n)-1 (mod n)
Algoritmo de Exponenciación Rápida
Supongamos que tenemos dos números naturales a y b, y queremos calcular ab. Lo normal es multiplicar a por sí mismo b veces, pero para valores muy grandes de b este algoritmo no nos sirve. Sin embargo, cualquier número puede representarse en forma binaria, con lo que de esta forma en vez de tener que calcular ab, tendiramos que calcular:
(prod)ni=0 a2^i.bi
Sabiendo que los bi solo pueden valer 0 ó 1, solo tendremos que multiplicar los a2^i correspondientes a los dígitos binarios de b que valgan 1.
El algoritmo de Exponienciación Rápida nos
queda de la siguiente forma:
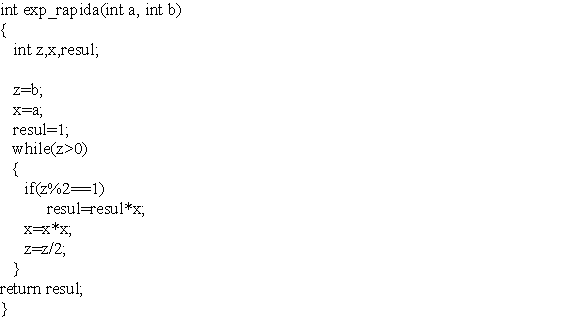
¿Cómo saber si un número es primo?
Mediante la factorización, que el problema inverso a la multiplicación, se podría saber si un número es primo o no pero no hay algoritmos eficientes de factorización. Sin embargo, sí existen algoritmos probabilísticos que permiten decir con un grado de certeza bastante elevado si un número cualquiera es primo o compuesto.
Uno de estos algoritmos es el algoritmo de Lehmann.
Algoritmo de Lehmann
Es uno de los algoritmos más sencillos para saber si un número p es primo o no. Para ello evaluamos dicho número(p) de la siguiente forma:
1. Escogemos un número a < p.
2. Calculamos b=a(p-1)/2 (mod p).
3. Si b distinto 1(mod p) y b distinto -1 (mod p), p no es
primo.
4. Si b º 1(mod p) ó
b º -1(mod p), la probabilidad de que p
sea primo es igual o superior al 50%.
Si evaluamos el algoritmo 10 veces la probabilidad de que p sea primo será de 210. En general repitiendo el algoritmo n veces, la probabilidad de que p sea primo será de 2n .
Para generar un número primo aleatoriamente podríamos utilizar el siguiente algoritmo:
1. Generar un número aleatorio p de n bits.
2. Poner a uno el bit más sigmificativo, y así garantizamos
que el número es de n bits, y el menos significativo también,
así aseguramos que el número será impar.
3. Intentar dividir el número p por una tabla de números
primos precalculados menores que 2000.
4. Si pasa el punto 3, entonces aplicamos 10 o 20 veces el test de
Lehmann.
Primos fuertes
Llamamos números primos fuertes aquellos que están relacionados de la siguiente forma:
1. El m.c.d (p-1,q-1) es muy pequeño.
2. p-1 -> p1 muy grande ; q-1 ->
q1 muy grande.
3. p -1 y q-1 son factores primos muy grandes.
4. p +1 y q+1 son factores primos muy grandes.
CRIPTOGRAFÍA
Criptográfia de llave privada.
Métodos de cifrado clásicos :
Cifrados monoalfabéticos: Se trata de todos los algoritmos criptográficos que sin desordenar los símbolos dentro del lenguaje generan una correspondencia única en todo el texto.
Cifrado de Cesar: Consiste en crear otro alfabeto a partir del original desplazando 3 caracteres cada letra del alfabeto, de forma que a la A le corresponde la D, a la B el E, y así sucesivamente.
Cifrados Polialfabéticos
El cifrado del carácter i-ésimo se obtiene desplazando la clave i-ésima. Corresponde a la aplicación cíclica de n cifrados monoalfabéticos.
Cifrado de Vigènere: La clave está constituida por una secuencia de símbolos k={k0, k1,..., kd-1} y que emplea la siguiente función de cifrado:
Ek(mi) = mi + k(i mod d) (mod n)
Siendo mi el i-ésimo símbolo del texto claro y n el cardinal del alfabeto de entrada.
ALGORITMO DES
El algoritmo DES es un algoritmo que cifra bloques de 8 bytes con una clave de 56 bits más 1 bit de paridad por cada byte de la clave. El DES se basa en las redes de Feistel, en concreto es una red de Feistel de 16 rondas.
Las redes de Feistel tienen la siguiente estructura:
Ki
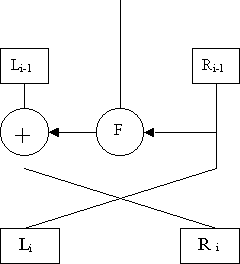
A Ri-1 se le aplica una función F , con el resultado hacemos un or exclusivo con L i-1 y de esta forma obtenemos Ri . L i se obtiene directamente a partir de R i-1,ya que R i-1 pasa a ser L i. La salida de esta ronda se utilizará como entrada de la siguiente ronda. Estas son las transformaciones que se deberán realizar:
Para cifrar:
L i = R i-1
Ri = L i-1 xor F(Ri-1, Ki)
Para descifrar:
Li-1 = R i xor F(Li, Ki)
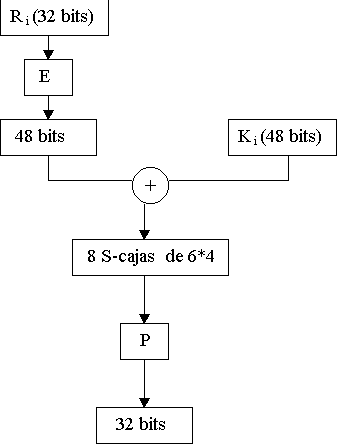
La función F se compone de una expansión,
convirtiendo los 32 bits iniciales de R i por 48, luego realiza
la operación or exclusiva con K i que tiene también
48 bits. Una vez realizada esta operación aplica 8 S-cajas de 6*4
bits y realiza una permutación convirtiendo los 48 bits en 32. El
esquema que sigue la funcion F es el siguiente:
Una de las desventajas del algoritmo DES es que tiene la clave muy corta. Para solucionar esto se creo que triple DES. Este algoritmo esta basado en tres iteraciones del DES, con lo que se consigue una longitud de clave de 128 bits, y que es compatible con DES simple.Si la clave de 128 bits está formada por dos claves iguales de 64 bits (C1=C2), entonces el sistema se comporta como un DES simple.
Modos de Operación para Algoritmos de Cifrado por Bloques
Modo ECB:
Consiste en dividir la cadena que se quiere codificar en bloques del tamaño adecuado y una vez hacho esto ciframos cada uno de los bloques obtenidos empleando la misma clave. El problema que nos puede generar el modo ECB es que los mensajes pueden presentar patrones repetitivos, con lo que el texto cifrado también los presentaría y resultaría peligroso por la posibilidad de un ataque estadístico que pudiera extraer bastante información.
Modo CBC:
Este modo incorpora un mecanismo de retroalimentación en el cifrado por bloques. En este caso se realizará una operación or exclusiva entre el bloque del mensaje que queremos codificar y el último criptograma codificado.
CIFRADOS ASIMÉTRICOS O DE LLAVE PÚBLICA
Los algoritmos asimétricos poseen dos claves; una privada (K) y otra pública (p). Una de ellas se emplea para cifrar y la otra para descifrar, de forma que lo que se cifra con una de ellas únicamente se puede descifrar con la otra. Las claves deben ser de tal forma que a partir de una debe ser imposible o casi imposible obtener la otra , ya que si no fuera así, no servirían de nada, pues al dar la pública estaríamos diciendo también la privada, con lo que estos algoritmos serían ineficientes.
Protección de la información:
Para proteger la información enviada un mensaje debería ser enviado de la siguiente forma. Supongamos dos usuarios, A y B, de tal forma que A quiere enviar un mensaje a B que sólo este pueda leer, es decir que este cifrado. En este caso A tiene que enviar el mensaje a B cifrado con la clave pública de B, ya que así B puede descifrar el mensaje con su llave privada y sólo B.
Autentificación:
Si suponemos que A envía un mensaje a B con la intención de que B sepa que el mensaje ha sido enviado por A y no por cualquier otra persona, lo que tendría que hacer A es enviar el mensaje correspondiente habiendo cifrado con su clave privada, de forma que cualquier persona que tenga su clave pública pueda abrirlo con la seguridad que la persona que ha enviado el mensaje es efectivamente A, de esta forma B comprobaría que A es realmente quién ha enviado el mensaje.
Si lo que se quisiera fuera tanto protección de la información como autentificación lo que debería hacer A es primero cifrar el mensaje con su clave privada, de esta forma quedaría autentificado, y posteriormente cifrar el mensaje con la clave pública de B. B al recibirlo tendría que descifrarlo primero con su llave privada, de forma que ya podría leer el mensaje, pero todavía no sabría si se lo habría enviado A, así que luego tendría que descifrar el mensaje con la llave pública de A, asegurándose de esta forma que efectivamente fue A quien le envió el mensaje.
El cifrado sería de la siguiente forma:
C = Epb(Eka(m))
Y descifrar se haría:
m = Dpa(Dkb(C))
ALGORITMO RSA
El algoritmo RSA esta basado en la dificultad de factorizar dos números grandes, así las claves pública y privada que se utilizan en este algoritmo se calculan a partir del producto de dos números primos grandes.
Para generar las claves pública y privada lo primero que hay que hacer es escoger aleatoriamente dos números primos grandes, p y q, y calcular su producto, que será n (n = p *q).
Ahora tenemos que escoger un número e que sea primo relativo con (p-1)(q-1), es decir que no comparte ningún factor con (p-1)(q-1). La clave pública del algoritmo será (e, n).
Para calcular la llave privada debemos calcular primero la inversa de e módulo (p-1)(q-1), que será d. Una vez calculado d, ya tenemos la clave privada que será (d, n).
Una codificación se realizará mediante la siguiente expresión:
C = me (mod n)
Y una decodificación mediante esta otra:
m = cd (mod n)
MÉTODOS DE AUTENTIFICACIÓN
Función resumen o hash
Esta es una función no inyectiva, que al aplicarla a un mensaje cualquiera da siempre como resultado una cadena de tamaño fijo.
La función resumen cumple las siguientes características:
Para saber esto tenemos dos tipos posibles de soluciones:
Un certificado es una clave pública y un identificador, firmados digitalmente por una autoridad de certificación, y su utilidad es demostrar que una clave pública pertenece a un usuario concreto.
Estándar X.509
El estándar X.509 sólo define la sintaxis de los certificados, por lo que no esta atado a ningún algoritmo en particular y esta compuesto de los siguientes campos:
Protocolos SSL y TLS
El protocolo SSL es un protocolo desarrollado originalmente por la empresa Netscape que sirve para dar una capa de seguridad mediante el estándar X.509 a cualquier comunicación a través de Internet. Se utiliza para dar mayor seguridad a las páginas web.
Objetivo principal: autentificación del servidor y el cifrado de datos.
Objetivo secundario: autentificación del cliente.
Cuando te conectas a una página web, lo que se tiene que garantizar con este protocolo es que te conectas a la página que estas indicando y que esta página se corresponde con la empresa a la que esperas que pertenezca.
¿Cómo funciona SSL?
Lo primero que se hace es la petición de inicio por parte del cliente hacia el servidor.
Luego se comprueba el common name viendo que coincide con la http solicitada, se comprueba también que la firma del certificado coincide con la firma de la empresa. Seguidamente se realiza el intercambio de protocolos criptográficos.
El cliente genera una llave se sesión con la clave pública de la empresa y la envía a la empresa como desafío, si la empresa puede descifrar la llave con su clave privada, entonces queda demostrado que realmente es la empresa.
Opcionalmente la empresa también puede autentificar al cliente de la misma forma, enviando un desafió al cliente.
La diferencia de acceder a una página web segura y una no segura poniendo https, que significa http + SSL, en vez de http.
TLS: Es un nuevo protocolo muy similar a SSL, mejorando algunos aspectos del SSL.
Mail seguro:SMIME
SMIME es una extensión de MIME, que además de permitir enviar correo electrónico con datos que no sean ASCII, como texto con formato, imágenes y ficheros adjuntos también permite el envío cifrado de datos bajo el protocolo SMTP y proporciona los siguientes servicios de seguridad:
Red: Una red es un sistema en el que distintos ordenadores
pueden comunicarse de forma directa. Las redes más extendidas son
las redes TCP/IP, por ejemplo Internet es una red TCP/IP. Este tipo de
redes funcionan con un modo de capas con la siguiente estructura:
|
|
|
|
|
|
|
|
|
|
|
|
Entre las aplicaciones hay una especial que es el DNS. Es la aplicación que se encarga de traducir las direcciones escritas como palabras a direcciones IP.
Respecto a la seguridad el perímetro de la zona de seguridad ha crecido enormemente, aunque todas las capas del protocolo TCP/IP son vulnerables. Las aplicaciones son las más vulnerables.
Problemas:
- Sniffing: Se pincha la red y se escucha la transmisión de datos a través de ella. Para evitar el sniffing lo mejor es cifrar los datos.
Hay dos formas de montar la criptografía en la
red:
1. Cifrado de enlace: El cifrado se realiza a nivel de la capa más
baja de la red. Aquí el clifrado se produce por tramas.
2. Cifrado extremo a extremo: La aplicación es quien cifra
los datos en caso que sea el emisor y quien los descifra en caso de ser
el receptor.
Hay varios puntos a tener en cuenta para protegerse en red en un sistema abierto:
Consiste en un conjunto de políticas y técnicas cuya misión es aislar al máximo parte de una red con en resto de la red. Para conseguir dicho aislamiento tenemos que establecer las políticas (indicar quien , que, en que condiciones, .... pasa). Hay dos tipos de políticas:
Esta técnica consiste en establecer un punto que
une la subred que deseamos proteger con el resto de la red, y en este punto
se establece un firewall que mediante unas reglas dejara pasar a unos paquetes
y denegará el paso de otros.
Virus: Podemos definir virus como programas que tienen las siguientes características:
Caballo de Troya :Son programas que en apariencia son benignos, pero esconden acciones de tipo malicioso. Así los caballos de Troya son programas que están ocultos en el interior de otros aparentemente inofensivos y cuando estos programas son ejecutados, los troyanos se lanzan para realizar acciones que el usuario no desea.
Gusanos: Código ejecutable que intenta sobrevivir dentro de la red. Es distinto que los virus, ya que estos no se pegan a ningún otro programa, es decir, no van asociados a ningún huésped, sino que utiliza vulnerabilidades de la red para expandirse.
Respecto a la seguridad contra los virus va a influir mucho la política de seguridad que empleemos a la hora de protegernos(hay que ser restrictivos a la hora de utilizar o descargar programas).
Los primeros virus surgen con MS-DOS. Paralelamente a estos también surgen los virus de Machintosh.
Virus en MS-DOS
Primera clasificación: Los virus se distinguen como virus
de arranque y virus de programa.
Virus de arranque:
El sector de arranque de los disquetes y la tabla de particiones del disco duro contienen un pequeño programa que se carga al encender el ordenador. Los virus de arranque copian el sector el sector original en algún otro lado y después se copian ellos en su lugar, dado que hay muy poco espacio suelen ocupar también algún otro sector del disco.
Para evitar que los sectores donde se copia el arranque original o alguna parte del virus sean sobrescritos, suelen marcarlos como defectuosos en la FAT.
Una vez activos en memoria van infectando todos los discos a los que se accede.
Virus de programa:
Estos virus se pegan a un programa y se ejecutan al arrancar dicho programa. Se contagian a través del paso de programas de unos sistemas a otros.
Tipos de programas:
.EXE: El virus se posiciona al final del fichero y cambia la cabecera para que apune a la zona donde se encuentra el virus, así se ejecuta el virus, luego devuelve el control y finalmente se ejecuta el programa.
Virus de acción directa: Se copia en memoria también
y además busca programas y archivos en el mismo directorio en el
que se encuentra y los infecta.
Un sistema operativo gestiona procesos, memoria, usuarios, ficheros, dispositivos, etc, y debe ser capaz de proteger unos de los otros.
El usuario de un sistema operativo se identifica en él mediante un identificador, que no tiene porque corresponder con ninguna característica del usuario. El identificador será un número (username) con el cuál el usuario se identificará en el sistema operativo, pero además de esto hará falta también autentificar al usuario, para ello se utilizará un password. Hay formas alternativas de identificación del usuario, por ejemplo mediante la identificación por huella, por tarjeta, por llave, etc.
Si no se toman precauciones pueden ser fáciles de averiguar. Algunas precauciones pueden ser las siguientes:
En UNIX tenemos 2 identificadores de usuario:
UID: identificador de usuario.
GID: identificador de grupo.
Al mismo tiempo estos identificadores pueden ser también efectivos o no. Es decir, que tenemos también:
EUID: identificador de usuario efectivo.
EGID: identificador de grupo efectivo.
Los dispositivos van embebidos en el sistema de archivos.
El sistema operativo tiene una especie de matriz (o tabla) donde se encuentran
los accesos de los usuarios a los recursos del sistema de la siguiente
forma:
| Usuario 1 | ... | Usuario n | |
| Recurso 1 |
el usuario i (i < n) en el recurso j (j < m) |
||
| .... | |||
| Recurso m | |||
Dado un fichero la forma de implementar esta lista varia de un sistema operativo a otro. En todos los ficheros se implementan las lista de control de acceso ( ACL ). Esta lista puede incluir tanto identificador de usuario como de grupo.
En UNIX el acceso a los ficheros está restringido según clases de usuarios. Las tres clases de usuarios son:
Propietario: Generalmente la persona que ha creado el fichero.
Grupo: El administrador del sistema agrupa a las personas por grupos.
Otros: Cualquier otro usuario del sistema.
Cada uno de los usuarios anteriores puede acceder a los ficheros de las siguientes formas:
Con permiso de lectura: Pueden ver el contenido del fichero.
Con permiso de escritura: Pueden modificar el contenido del fichero.
Con permiso de ejecución: Pueden ejecutar un fichero.
Los permisos se pueden dar a los ficheros mediante el siguiente comando:
Chmod numero nombre_fichero
Donde número es un número de tres dígitos octales que representan los permisos y nombre_fichero es el fichero al que le damos dichos permisos.
A los permisos anteriormente explicados tenemos que añadir dos permisos:
t: Se utiliza principalmente en directorios. Implica que una persona solo va a poder incidir sobre ficheros que son suyos. Se utiliza por ejemplo en el fichero temporal /tmp para que un usuario no pueda borrar ficheros que no le pertenezcan.
s: Afecta a los ficheros ejecutables, es una propiedad añadida al atributo x y puede afectar al usuario o al grupo.
UID -> cualquiera
EUID -> propietario